
Programming Standards - Data Processing
Defining Output Data
- Use same structure & naming conventions across all fields (e.g.,
fieldname,label,fieldtype,width). - Use meaningful
fieldnameand clear, user-friendlylabel. - Avoid abbreviations or vague names—this makes reports easier to understand and maintain.
- Include metadata like
fieldtypeandoptionsfor accurate rendering and linking.
❌ Incorrect Way: Poorly Defined Output
la_columns = [ {"fieldname": "sales_order", "label": _("Sales Order"), "fieldtype": "Data", "options": "Sales Order", "width": 140}, # ❌ field type is wrong {"fieldname": "customer", "label": _("Customer Name"), "fieldtype": "Link", "options": "Customer", "width": 180}, # ❌ field name is wrong {"fieldname": "delivery_date", "label": _("Delivery Date"), "fieldtype": "Date", "width": 120}, {"fieldname": "item_code", "label": _("Item Code"), "fieldtype": "Link", "options": "Item", "width": 160}, {"fieldname": "order_value", "label": _("Order Value"), "fieldtype": "Currency", "width": 120}, {"fieldname": "po_date", "label": _("PO Date"), "fieldtype": "Date", "width": 100},]Wrong Practice:
- Give the field names and their corresponding field types accurately based on the database.
✅ Correct Way: Well-Defined and Structured Output
la_columns = [ {"fieldname": "sales_order", "label": _("Sales Order"), "fieldtype": "Link", "options": "Sales Order", "width": 140}, {"fieldname": "customer_name", "label": _("Customer Name"), "fieldtype": "Link", "options": "Customer", "width": 180}, {"fieldname": "delivery_date", "label": _("Delivery Date"), "fieldtype": "Date", "width": 120}, {"fieldname": "item_code", "label": _("Item Code"), "fieldtype": "Link", "options": "Item", "width": 160}, {"fieldname": "order_value", "label": _("Order Value"), "fieldtype": "Currency", "width": 120}, {"fieldname": "po_date", "label": _("PO Date"), "fieldtype": "Date", "width": 100},]Best Practices Applied:
- All fields use consistent and complete keys:
fieldname,label,fieldtype,width - Proper localization using
_()for labels - Follows consistent naming (
snake_case) fieldtypeproperly declared (Link,Float,Date, etc.)optionsincluded for allLinkfields
Sample Output:
| Sales Order | Customer Name | Delivery Date | Item Code | Order Value | PO Date |
|---|---|---|---|---|---|
| SAL-ORD-2025-00001 | ABB AG | 15-06-2025 | DTTHZ2/800/10/28/400/75 | 12.500,00 | 20-05-2025 |
| SAL-ORD-2025-00002 | John | 01-07-2025 | DTTHZ3/630/20/22/450/85 | 9.800,00 | 25-05-2025 |
Initialization and Clearing fields
When building structured data from complex objects like sales orders and their line items initializing and clearing fields at the start of processing each item is critical for the following reasons:
- It ensures each data entry starts from a clean state, avoiding leftover values from previous iterations.
- Makes the data consistent and reliable, which is especially important when some fields are optional or conditionally filled.
Scenario:
When processing a sales order with multiple items, not every item will have all fields filled. Initializing each item’s data structure beforehand ensures all expected fields exist, avoids leftover data from previous items, and keeps the output consistent and reliable.
❌ Incorrect Way
la_data = []for ld_sales_order in la_sales_order: ld_row = {} # Only declared once, outside the loop for ld_item in ld_sales_order.items: ld_row["sales_order"] = ld_sales_order.name ld_row["customer_nmae"] = ld_sales_order.customer_name ld_row["delivery_date"] = ld_item.delivery_date ld_row["item_code"] = ld_item.item_code ld_row["order_value"] = ld_item["order_value"] ld_row["po_date"] = ld_sales_order.po_date if "description" in ld_item: ld_row["description"] = ld_item.description
la_data.append(ld_row) # Appends the same dictionary object every timeWHY:
- Only one dictionary
rowis created. - Each iteration overwrites the same object.
datawill contain multiple references to the same final row.- The output will look like this:
| No | Sales Order | Customer Name | Delivery Date | Item Code | Order Value | PO Date | Note (Description) |
|---|---|---|---|---|---|---|---|
| 1 | SAL-ORD-2025-00001 | ABB AG | 2024-01-05 | ITEM-001 | 100 | 2024-01-01 | First item |
| 2 | SAL-ORD-2025-00001 | ABB AG | 2024-01-06 | ITEM-002 | 150 | 2024-01-01 | First item ❌ |
| 3 | SAL-ORD-2025-00002 | John | 2024-02-10 | ITEM-003 | 300 | 2024-02-01 | Special instructions |
✅ Correct Way
def fn_clear_line_items(id_field): #clearing only line items id_field["delivery_date"] = id_field["item_code"] = id_field["order_value"] = id_field["description"] = "" return id_fieldla_data = []for ld_sales_order in la_sales_order: for ld_item in ld_sales_order.items: # Step 1: Initialize the row with empty/default values ld_row = { "sales_order": ld_sales_order.name, # from sales order header "customer_name": ld_sales_order.customer_name, # from sales order header "delivery_date": "", "item_code": "", "order_value": "", "po_date": ld_sales_order.po_date # from sales order header, "description": "" }
# Step 2: Assign actual values ld_row["delivery_date"] = ld_item.delivery_date ld_row["item_code"] = ld_item.item_code ld_row["order_value"] = ld_item.order_value ld_row["description"] = ld_item.description # Step 3: Append the populated row to the data list la_data.append(ld_row) # Step 4: Clear line item fields to prevent data carryover in next iteration ld_row = fn_clear_line_items(ld_row)WHY
- Step 1 (Initialization) ensures that all fields are clean before data is assigned.
- Prevents carry-over bugs from reused fields or dictionaries.
- Makes the code explicit and easier to maintain, especially when fields are optional or filled conditionally.
| No | Sales Order | Customer Name | Delivery Date | Item Code | Order Value | PO Date | Note (Description) |
|---|---|---|---|---|---|---|---|
| 1 | SAL-ORD-2025-00001 | ABB AG | 2024-01-05 | ITEM-001 | 100 | 2024-01-01 | First item |
| 2 | SAL-ORD-2025-00001 | ABB AG | 2024-01-06 | ITEM-002 | 150 | 2024-01-01 | |
| 3 | SAL-ORD-2025-00002 | John | 2024-02-10 | ITEM-003 | 300 | 2024-02-01 | Special instructions |
Binary Search: Find Leftmost Occurrence in a Sorted List
Description
- Used to find the leftmost index of a given key in a sorted list of dictionaries.
- Uses the binary search algorithm for efficient lookup (
O(log n)complexity). - Requires that the list is pre-sorted by the specified key (
i_key). - Returns the index of the first (leftmost) matching element, or
-1if not found. - Useful for handling duplicates where the earliest position is required.
❌ Incorrect Way:
# Searching linearly or without ensuring sortingfor l_idx, ld_order in enumerate(sales_orders): if ld_order["customer_name"] == "ABB AG": return l_idxWhy it’s incorrect:
- Inefficient for large datasets (O(n) time complexity).
- Doesn’t guarantee the leftmost occurrence in all cases.
- Assumes value is directly accessible and data is sorted - not generic.
✅Correct Way:
def fn_binary_search_leftmost(ia_sorted_list, i_key, i_search_key): """ Perform binary search to find the leftmost occurrence of a value in a sorted list of dictionaries. Parameters: ia_sorted_list (list[dict]): Sorted list of dictionaries. i_key (str): Dictionary key to compare. i_search_key (Any): Value to search for. Returns: int: Leftmost index of the matching element, or -1 if not found. """ l_low = 0 l_high = len(ia_sorted_list) - 1 l_result = -1 while l_low <= l_high: l_mid = (l_low + l_high) // 2 ld_mid_dict = ia_sorted_list[mid] if ld_mid_dict[i_key] < i_search_key: l_low = l_mid + 1 elif ld_mid_dict[i_key] > i_search_key: l_high = l_mid - 1 else: l_result = l_mid l_high = l_mid - 1 # Continue search on the left side return l_resultla_sales_orders = [ {"sales_order": "SAL-ORD-2025-00001", "customer_name": "ABB AG", "delivery_date": "15-06-2025", "item_code": "DTTHZ2/800/10/28/400/75", "order_value": "12.500,00", "po_date": "20-05-2025" }, {"sales_order": "SAL-ORD-2025-00002", "customer_name": "John", "delivery_date": "01-07-2025", "item_code": "DTTHZ3/630/20/22/450/85", "order_value": "9.800,00", "po_date": "25-05-2025" }, {"sales_order": "SAL-ORD-2025-00003", "customer_name": "John", "delivery_date": "05-07-2025", "item_code": "DTTHZ3/630/20/22/450/90", "order_value": "10.200,00", "po_date": "26-05-2025" }]la_sales_orders.sort(key=lambda x: x["customer_name"])# Binary Searchl_index = fn_binary_search_leftmost(la_sales_orders, "customer_name", "John")# Output the matching recordif l_index != -1: log(la_sales_orders[l_index])else: log("Customer not found.")Sample Output
{'customer_name': 'John', 'sales_order': 'SAL-ORD-2025-00002'}Explanation Use Case: A company wants to generate monthly reports for a specific customer.
Context:
- You have a list of 10,000+ sales_orders, sorted by “customer_name”.
- Customer “John” may have placed multiple orders.
- You need to quickly find all of John’s orders without scanning the whole list.
Steps:
- Use fn_binary_search_leftmost to find the first index of “John”.
- Iterate forward to collect all orders where “customer_name” == ‘John’”.
- Stop when the customer name changes (since list is sorted).
Why Binary Search is Powerful
| Feature | Binary Search | Linear Search |
|---|---|---|
| Time Complexity | O(log n) | O(n) |
| Works on Sorted Data | ✅ | ✅ |
| Finds Leftmost Match | ✅ | ❌ (requires extra logic) |
| Scales with Data | ✅ | ❌ |
Extracting Unique Values from a Dataset
- When processing datasets, it’s important to eliminate duplicates early — especially when you’re working with values like customer names, item codes, or IDs.
- Ensures uniqueness improves performance by avoiding redundant processing.
Scenario You have a dataset containing multiple sales orders. Each sales order includes customer details. Your goal is to extract a unique list of customers from this sales order dataset for further use
❌ Incorrect Way:
la_columns = [ {"sales_order": "SAL-ORD-2025-00001", "customer_name": "ABB AG", "delivery_date": "15-06-2025", "item_code": "DTTHZ2/800/10/28/400/75", "order_value": "12.500,00", "po_date": "20-05-2025"}, {"sales_order": "SAL-ORD-2025-00002", "customer_name": "John", "delivery_date": "01-07-2025", "item_code": "DTTHZ3/630/20/22/450/85", "order_value": "9.800,00", "po_date": "25-05-2025"}, {"sales_order": "SAL-ORD-2025-00003", "customer_name": "ABB AG", "delivery_date": "20-07-2025", "item_code": "DTTHZ4/900/30/35/500/90", "order_value": "15.200,00", "po_date": "30-05-2025"},]# Wrong way:def fn_get_unique(id_data_set, i_key): la_unique = [] for it_data in id_data_set: if i_key in it_data: l_value = it_data[i_key] if l_value not in la_unique: # ❌ Slow linear search every time la_unique.append(l_value) return la_unique
la_unique_customers = fn_get_unique(la_columns, "customer_name")print(la_unique_customers)Sample Output:
['ABB AG', 'John']WHY
- Slower and consumes more CPU time as dataset grows.
- As dataset size grows, the repeated
value not in unique_valuescheck causes slow performance (O(n²) complexity).
✅ Correct Way:
This uses a set to collect only unique values.
def fn_get_unique(id_data_set, i_key): la_unique = list(set(it_data[i_key] for it_data in id_data_set if i_key in it_data)) return la_uniquela_unique_customers = fn_get_unique(la_columns, "customer_name")print(la_unique_customers)Sample Output:
['ABB AG', 'John']WHY
- Sets guarantee uniqueness and provide fast membership checks (O(1) average).
- This method scales well for large datasets.
Avoid frappe calls in the for loops
- When processing data (e.g., extracting customer details), do NOT query or loop over the database/dataset repeatedly for the same data.
- Instead, fetch the dataset once and then use techniques like extracting unique customers to work efficiently.
- This avoids performance issues and redundant operations, especially when customers have multiple sales orders.
Example:
- We have a dataset called
la_columns, which contains sales order records. Each record includes customer name, delivery date, item code, order value, and PO date. Some customers can have multiple sales orders.Now, say we want to fetch customer details (e.g., from a database).
❌ Incorrect Way: Query or Loop Repeatedly for Each Customer
la_columns = [ {"sales_order": "SAL-ORD-2025-00001", "customer_name": "ABB AG", "delivery_date": "15-06-2025", "item_code": "DTTHZ2/800/10/28/400/75", "order_value": "12.500,00", "po_date": "20-05-2025"}, {"sales_order": "SAL-ORD-2025-00002", "customer_name": "John", "delivery_date": "01-07-2025", "item_code": "DTTHZ3/630/20/22/450/85", "order_value": "9.800,00", "po_date": "25-05-2025"}, {"sales_order": "SAL-ORD-2025-00003", "customer_name": "ABB AG", "delivery_date": "20-07-2025", "item_code": "DTTHZ4/900/30/35/500/90", "order_value": "15.200,00", "po_date": "30-05-2025"},]
for ld_record in la_columns: #fetching the customer data for each sales order la_details = frappe.get_doc("Customer", ld_record.customer_name) print(la_details)WHY:
- This can lead to fetching customer data that was already retrieved earlier. For example, if customer ID ‘AAB AG’ was processed in a previous step and appears again in the current loop, we end up fetching the same data again unnecessarily.
- This method may result in performance inefficiencies.
✅ Correct Way: Query Unique Customers Only Once
#extract unique customers from the la_columnsla_unique_customers = set(ld_record["customer_name"] for ld_record in la_columns)la_details = frappe.get_list("Customer", filters={"name": ["in", la_unique_customers]}, fields=["name", "territory", "email_id"])WHY:
- Extract all unique customer records using
set(), then query the customer master using anINfilter. - As a result, it minimizes database hits, improves response time, and optimizes overall performance.
Count Sales Orders for a Single Customer
Description
- Counts how many sales orders exist for a specific customer from an already fetched list (array) of sales orders.
- Useful when working with data you already have in memory.
- Do not use this approach for very large datasets directly in memory, as it may impact performance for large data, prefer database queries with filters.
❌ Incorrect Way
def fn_get_customer_order_count(ia_sales_orders, i_customer_name): # Incorrect: uses count() on a list of customer names, but # creates a temporary list and does two passes unnecessarily. la_customer_names = [ld_order["customer_name"] for ld_order in ia_sales_orders] return la_customer_names.count(i_customer_name)fn_get_customer_order_count(la_sales_orders, "customer_name")WHY:
- Creates an intermediate list (
la_customer_names), using extra memory. - Performs two passes: one to build the list, another to count occurrences.
- Inefficient and doesn’t scale well for large datasets in memory.
✅ Correct Way
def fn_get_customer_order_count(ia_sales_orders, i_customer_name): """ Count the number of sales orders for a given customer from an already fetched list. Parameters: ia_sales_orders (list[dict]): List of sales order dictionaries with 'customer_name' keys. i_customer_name (str): Customer name to count. Returns: int: Number of matching sales orders. """ return sum(1 for ld_order in ia_sales_orders if ld_order["customer_name"] == i_customer_name)fn_get_customer_order_count(la_sales_orders, "John")WHY:
- Memory-efficient: Doesn’t create any extra list.
- Single-pass: Evaluates and counts in one loop.
- Scalable: Works well even for large datasets.
Sample Input:
la_sales_orders = [ { "sales_order": "SAL-ORD-2025-00001", "customer_name": "ABB AG", "delivery_date": "15-06-2025", "item_code": "DTTHZ2/800/10/28/400/75", "order_value": "12.500,00", "po_date": "20-05-2025" }, { "sales_order": "SAL-ORD-2025-00002", "customer_name": "John", "delivery_date": "01-07-2025", "item_code": "DTTHZ3/630/20/22/450/85", "order_value": "9.800,00", "po_date": "25-05-2025" }, { "sales_order": "SAL-ORD-2025-00003", "customer_name": "John", "delivery_date": "05-07-2025", "item_code": "DTTHZ3/630/20/22/450/90", "order_value": "10.200,00", "po_date": "26-05-2025" }]l_customer_name = "John"l_order_count = fn_get_customer_order_count(la_sales_orders, l_customer_name)print(f"Sales order count for {l_customer_name}: {l_order_count}")Sample Output:
Sales order count for John: 2frappe utility functions for date
Frappe provides utility functions for handling dates and times efficiently, enabling developers to work with business logic involving delivery dates, document validity, weekly schedules, etc.
Key functions:
- frappe.utils.getdate(date_str)
- frappe.utils.date_diff(end_date, start_date)
- getdate().isocalendar() – for getting ISO week/year/day-of-week.
1. getdate: Converts a string or datetime into a Python date object. Ensures consistent format for all date operations within Frappe apps.
❌ Incorrect Way: Using raw strings or datetime objects without conversion:
l_date = "2025-05-29"print(l_date)✅ Correct Way: Use getdate() to standardize all date inputs
l_date_obj = frappe.utils.getdate("2025-05-04")print("getdate:", l_date_obj)Sample Output:
getdate: 2025-05-042. date_diff: Calculates the number of days between two dates. Accepts both date strings or Python date objects.
❌ Incorrect Way: Manually calculating days difference without converting strings to date objects:
l_diff = ("2025-06-01" - "2025-05-29").days✅ Correct Way:
Use date_diff() to safely compute days difference with proper date conversion.
l_date_1 = "2025-05-25"l_date_2 = "2025-05-20"#use abs to prevent negative result (ex: -5)l_date_difference = abs(frappe.utils.date_diff(l_date_2, l_date_1))print("date_diff:", l_date_difference)Sample Output:
date_diff: 53. isocalendar:
Returns a tuple (ISO year, ISO week number, ISO weekday) for a given Python date object. Helps in week-based date processing.
❌ Incorrect Way: Attempting to manually calculate week numbers or weekdays, leading to errors or complex code.
l_week_num = (l_date_obj.day - 1) // 7 + 1✅ Correct Way:
Use the built-in .isocalendar() method on a date object to get accurate ISO calendar details.
la_iso_calendar = frappe.utils.getdate("2025-05-29").isocalendar()print("isocalendar:", (la_iso_calendar[0], la_iso_calendar[1], la_iso_calendar[2]))Sample Output:
isocalendar: (2025, 22, 4)Code Reusability in Data processing
- Writing modular functions.
- Logic is written once and reused across multiple parts of our application.
- Prevents code duplication and manual repetition.
Description:
- Consistency: Ensures the same data processing logic (e.g., sorting, filtering, formatting) gives consistent results in all reports, dashboards, and APIs.
- Testability: Small, focused functions are easier to unit test and debug.
- Maintainability: Fix or improve the logic in one place, and the change reflects everywhere it’s used.
- Efficiency: Saves development time — no need to rewrite similar logic repeatedly.
- Modularity: Leads to cleaner, more readable, and better-structured code.
- Scalability: Easily extendable when building new features or reports.
Scenario: Say that you want to fetch customer master details from a list of sales orders. The same customer may appear in multiple sales orders.
❌ Incorrect Way:
def fn_get_customer_details(it_sales_order_list): # Extract unique customers manually (logic is not reusable) la_unique_customers = list(set([it_d['customer'] for it_d in it_sales_order_list])) filters = { 'name': ('IN', la_unique_customers), } ld_customer = frappe.get_all( 'Customer', fields=['name', 'customer_group', 'territory'], filters=filters) return ld_customerWhy:
- The logic to extract unique entries is repeated.
- If you need to extract unique
items,territories, or any other key elsewhere, you’d need to duplicate this logic again.
✅ Correct Way:
def fn_get_unique(it_table, i_key): la_unique = list(set([it_d[i_key] for it_d in it_table])) return la_uniquedef fn_get_customer_details(it_sales_order_list): # ✅ Reuse the get_unique la_unique_customers = get_unique(it_sales_order_list, 'customer') filters = { 'name': ('IN', la_unique_customers), } ld_customer = frappe.get_all( 'Customer', fields=['name', 'customer_group', 'territory'], filters=filters) return ld_customer
def fn_get_territory_details(it_sales_order_list): # ✅ Reuse the get_unique la_unique_territories = get_unique(it_sales_order_list, 'territory') filters = { 'name': ['in', la_unique_territories], } ld_territories = frappe.get_all( 'Territory', fields=['name'], filters=filters )WHY:
- Reusable utility function:
get_uniquecan be used across modules (e.g., for customers, territory). - Avoids duplication: Logic is written once and reused (Don’t Repeat).
- Easy to maintain: Any optimization or fix to uniqueness logic is done in one place.
- Clean and readable: Separates utility logic from business logic.
Use Case Scenario
A company stores 1000+ sales orders, each linked to a customer by a unique customer. The sales orders are sorted by customer. When a support agent wants to find all orders for a particular customer quickly, the system uses binary search to find the first order by that customer and then collects all matching orders efficiently.
def fn_binary_search_sales_order(ia_orders, i_target_order): low = 0 high = len(ia_orders) - 1 while low <= high: mid = (low + high) // 2 mid_order = ia_orders[mid]['sales_order'] if mid_order == i_target_order: return ia_orders[mid] # Found elif mid_order < i_target_order: low = mid + 1 else: high = mid - 1 return None # Not found
def find_sales_order(ia_sales_orders, i_target_order_id): # Step 1: Sort orders by sales_order (if not sorted already) la_sorted_orders = sorted(ia_sales_orders, key=lambda x: x['sales_order']) # Step 2: Use binary search on sorted list return fn_binary_search_sales_order(la_sorted_orders, i_target_order_id)
l_target_order_id = "SAL-ORD-2025-00456"ld_result = find_sales_order(la_sales_orders, l_target_order_id)if result: print("Sales Order Found:") for l_key, l_val in ld_result.items(): print(f"{l_key}: {l_val}")else: print(f"Sales order {l_target_order_id} not found.")How Binary Search Works:
| Step | Low | High | Mid | Mid Value | Compare (SO-00456) | Action |
|---|---|---|---|---|---|---|
| 1 | 0 | 999 | 499 | SO-00500 | 00456 < 00500 | Move left → high = 498 |
| 2 | 0 | 498 | 249 | SO-00250 | 00456 > 00250 | Move right → low = 250 |
| 3 | 250 | 498 | 374 | SO-00375 | 00456 > 00375 | Move right → low = 375 |
| 4 | 375 | 498 | 436 | SO-00437 | 00456 > 00437 | Move right → low = 437 |
| 5 | 437 | 498 | 467 | SO-00468 | 00456 < 00468 | Move left → high = 466 |
| 6 | 437 | 466 | 451 | SO-00452 | 00456 > 00452 | Move right → low = 452 |
| 7 | 452 | 466 | 459 | SO-00460 | 00456 < 00460 | Move left → high = 458 |
| 8 | 452 | 458 | 455 | SO-00456 | ✅ Match found | Stop |
Charts in Reports
Charts in reports help visualize complex datasets, making trends and comparisons easier to understand at a glance.
Charts are commonly used to:
- Track sales, capacity, or inventory over time (weeks, months, quarters).
- Compare different categories or groups.
- Show planned vs actual metrics.
- Highlight key performance indicators (KPIs).
❌ Incorrect Way:
- Hardcoding chart height and Y-axis markers without adjusting to data scale.
- Mixing stacked bars and line charts without using
type: "axis-mixed". - Overloading stacked bars with too many datasets causing clutter.
- Ignoring consistent colors and label formatting.
ld_chart_data = { "data": { "labels": ["22", "23", "24"], # Week numbers as strings, but unsorted or incomplete "datasets": [ {"name": "Power A", "chartType": "bar", "values": [10, 20, None]}, # Missing data {"name": "Weekly Capacity", "chartType": "line", "values": [40, 45, 42]}, ] }, "chartOptions": {"height": 40}, # Too small height for mixed data "yMarkers": [{"label": "Target", "value": "100"}], # Marker does not reflect real data max "barOptions": {"stacked": True}, # No type axis-mixed, so line and bar axes clash}✅Correct Way:
- Use
type: "axis-mixed"when combining line and bar charts. - Dynamically calculate max Y-axis values and adjust
yMarkersaccordingly. - Ensure all labels (e.g., weeks) are continuous and sorted.
- Use flexible chart height or set based on content.
- Limit datasets for readability and use consistent colors.
ld_chart_data = { "type": "axis-mixed", "data": { "labels": ["3", "4", "5"], "datasets": [ {"name": "Power A", "chartType": "bar", "values": [10, 20, 15]}, {"name": "Power B", "chartType": "bar", "values": [15, 10, 25]}, {"name": "Weekly Capacity", "chartType": "line", "values": [40, 45, 42]}, ] }, "chartOptions": {"height": 250}, "yMarkers": [ { "label": "Max Capacity", "value": "55", "options": {"labelPos": "left"} } ], "barOptions": {"stacked": True}, "colors": ["#db2777", "#ffa3ef", "#0891b2"],}Sample Output:
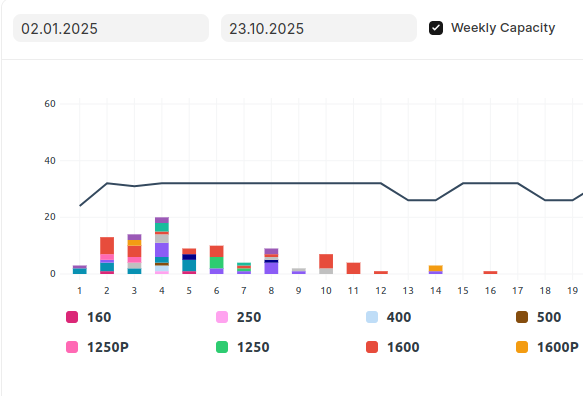
- X-axis labels: Week numbers 3, 4, 5.
- 2 stacked bar series: “Power A” and “Power B” shown as stacked bars.
- 1 line series: “Weekly Capacity” drawn over the bars.
- Horizontal marker: at value
55, labeledMax Capacityon the Y-axis. - Y-axis scale: Automatically scales to cover up to
55.